Performance fuzzing compilers a journey with kotlinc
Compiler and IDE performance are paramount to a good developer experience. Howerver, optimizing a modern compiler is tricky due to the sheer size and complexity: just the frontend of kotlinc the Kotlin compiler weighs in at 80KLOC.
This makes expert-driven optimization expensive and suggests the need for improved tooling.
Indeed, the security community is well familiar with fuzzing — automatically feeding a program randomized inputs to find crashes, memory corruption, and other misbehaviour. The discovered interesting inputs are then investigated by experts.
Inspired by a 2018 ISSTA paper, we worked with Jetbrains Research’s MLSE lab to apply fuzzing to the problem of finding performance anomalies in kotlinc.
Fuzzing redux
Fuzzing methods differ on three axes:
- whether they generate inputs from scratch or mutate existing ones
- how the input format structure is encoded
- how much feedback they get from the target program
For instance, the poster child of fuzzing is AFL, a mutation-based unstructured graybox fuzzer. To use it, one seeds it with samples of input format (i.e. a few PNG images to fuzz libpng) which it then mutates with built-in heuristics. The user need not supply a specification of PNG — AFL hooks into the program to observe its execution graph in response to each input and optimizes inputs so as to maximize graph coverage.
Source code in a high-level language is a way more structured input than normally tackled by fuzzers, where structure interdependency.
Imagine generating a network packet: it has a structured header and a data section. The fuzzer is free to generate any flags permutations or mutate source/dest leaving the data as-is; the only dependence it has to learn is the relation between header.packet_length and actual length(data) — if they don’t match, the packet will be rejected early and thus the bulk of the program unexplored.
The property-based testing crowd frames this as sampling from the generator domain and filtering only valid inputs encoded in an executable oracle. When the generator domain is set of valid inputs, random generation becomes intractable.
Theory in Kotlin practice
When working with highly-structured data, it is tempting to provide the generator an explicit model of the format. Unfortunately, Kotlin has no formal description of the type system, and designing one is very much out of scope of a fuzzing project. An ANTLR grammar is available though!
This rules out whitebox fuzzing.
Generally, the blacker the fuzzing, the faster you have to fuzz to find interesting cases (AFL generally works with at least 1000 samples/sec). kotlinc is slow, compiling on the order of , so blackbox would seem intractable.
Prior work shows neural generation of source code coupled with a quick pre-filter make for a practical blackbox fuzzer. That is, a neural generator + a fast heuristic oracle generate valid enough inputs to make fuzzing of even slow programs tractable.
Still, OpenCL is much simpler than Kotlin. We also could not quickly reproduce authors’ results; and so moved on to graybox approaches. We currently believe a DeepSmith-Kotlin to be viable, but computationally expensive.
Going graybox
Exploration of the program graph à la AFL sounds like a great fit for a compiler: one expects to exercise various analysis and optimisation routines when optimizing inputs for breadth.
Our first executable result was a kotlinc driver for JQF, a port of AFL for Java (ISSTA 2019). JQF’s graybox instrumentation further reduced performance to .
Could we remedy that with very good input generation?
We tried two strategies:
- domain-general semantic fuzzing with Zest
- domain-specific seeds and mutators
We found Zest doesn’t work with slow feedback (convergence is much too slow).
Domain-specific mutators
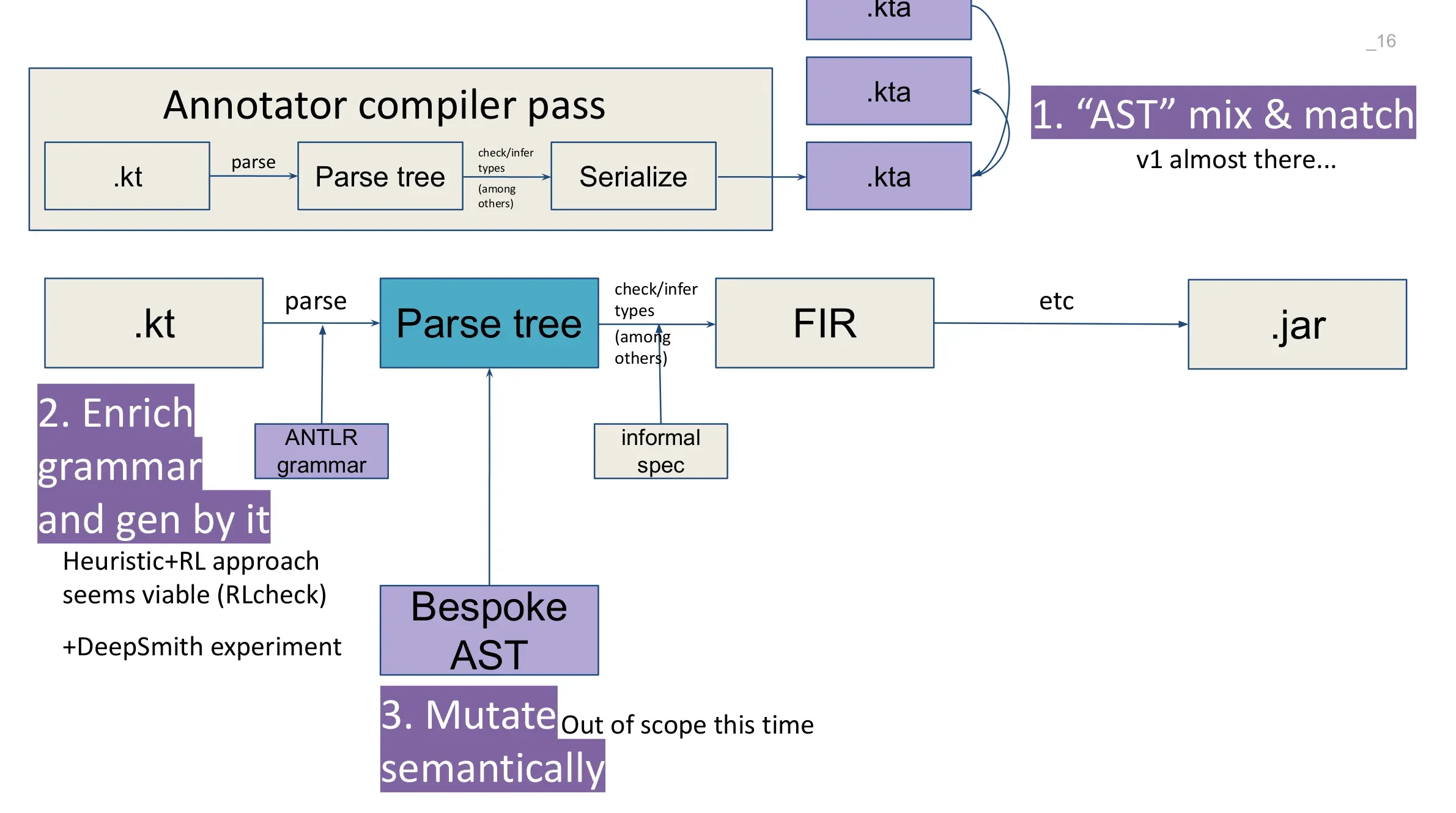
Here’s a diagram of kotlinc’s internal representations:
Observe we can pick a layer to start generation at. For instance, to generate Kotlin sources we could start with the ANTLR grammar mentioned above.
We can even isolate a part of the compiler and only fuzz that!
For this project, we bootstrapped from the compiler testsuite (that’s kotlin/compiler/testData and kotlin/benchmarks) and implemented mutation through recombination.
Our technique annotates the seed files with a source map of type information extracted from the compiler. This lets us separate slow-offline-correct analysis provided by the compiler from fast-online-heuristic analysis we do.
The recombinator is cognizant of types and scopes and only replaces item for if and .
We find this approach promising and look forward to putting in some additional engineering work to make it scale to hundreds of cores (remember, kotlinc is slow).
In this case study, we saw how Multicore evaluated the landscape of fuzzing and applied their findings to fuzzing kotlinc, an industrial compiler. In the span of a three months’s contract, we prototyped two approaches inspired by the latest research and earmarked future work directions.
This work reflects our values of striving for multiplicative impact — an improvement in kotlinc improves every Kotlin developer’s experience — and applying state-of-the art techniques.
Additional (raw) research notes are available at wldhx/kotperffuzz.